
A multi-site indexer cluster spans multiple physical sites, such as data centers. Each site has its own set of peer nodes and search heads and each site also obeys site-specific replication and search factor rules. At its core, multi-site indexer clustering involves the deployment of multiple indexers across geographically dispersed locations, working in tandem to handle indexing operations efficiently. This approach aims to enhance data availability, fault tolerance, and performance by distributing indexing tasks among interconnected nodes.
Understanding multi-site indexer clustering
This configuration typically involves 0 to 63 sites, wherein indexing tasks are distributed across these sites. Three crucial concepts in this setup are the site search factor, site replication factor and search affinity.
Site Search Factor (SSF): This factor determines the number of sites required to fulfill search requests. It indicates the level of redundancy needed for search capability. For instance, an SSF of 3 means that three sites must be available to perform searches effectively. This factor ensures fault tolerance and high availability in search operations by replicating data across multiple sites.
Site Replication Factor (SRF): This factor specifies the number of sites where data should be replicated. It defines the redundancy level for the data across the multi-site environment. For example, an SRF of 2 signifies that data is replicated across two different sites, ensuring data availability and resilience against site failures.
Search Affinity:
Search Affinity refers to the preference or priority given to nearby or local sites when executing search operations. When a search is initiated within a multi-site Splunk deployment, the system can be configured to prioritize or favor the utilization of resources (such as indexing and computing power) from sites that are geographically closer or local to the search request origin.
This approach minimizes latency and network overhead by attempting to execute searches using resources available in the same geographical area or within the local network segment. By doing so, it optimizes search performance by reducing the reliance on distant or remote sites, thereby potentially improving query response times and overall system efficiency.
Key components and architecture
The architecture of multi-site indexer clustering typically comprises several essential components:
Indexer Nodes: These are individual instances responsible for indexing and managing data. Nodes can be deployed across different sites or regions, interconnected to form a cluster.
Cluster Master: A central control unit overseeing the indexer nodes, responsible for coordination, load balancing, and data distribution among the nodes.
Communication Protocol: Robust communication protocols, often based on high-speed networks or protocols like TCP/IP, facilitate seamless interaction among nodes, ensuring efficient data transfer and synchronization.
There are two modes of clustering in multi-site:
- CLI mode
- .conf mode
CLI mode:
The Command Line Interface (CLI) mode refers to the ability to interact with Splunk software through command-line commands. It allows administrators to perform various management tasks related to setting up, configuring, monitoring, and maintaining a Splunk cluster.
Execute the following on Manager node to set the cluster manager:
/opt/splunk/bin/splunk edit cluster-config -mode manager -multisite true -available_sites site1,site2 -site site1 -site_replication_factor origin:2,total:3 -site_search_factor origin:1,total:2
Execute the following on Peer nodes to add them to the cluster:
/opt/splunk/bin/splunk edit cluster-config -mode peer -site site1 -manager_uri https://<cluster_master_ip>:8089 -replication_port 9887/opt/splunk/bin/splunk edit cluster-config -mode peer -site site2 -manager_uri https://<cluster_master_ip>:8089 -replication_port 9887Adding Search Heads to the cluster:
/opt/splunk/bin/splunk edit cluster-config -mode searchhead -site site1 -manager_uri https://<cluster_master_ip>:8089/opt/splunk/bin/splunk edit cluster-config -mode searchhead -site site2 -manager_uri https://<cluster_master_ip>:8089Command for setting cluster label:
splunk edit cluster-config -cluster_label <CLUSTER LABEL>
.conf files:
In a multi-site clustering setup in Splunk, several configuration files (commonly ending with a .conf extension) play crucial roles in defining and managing various aspects of the clustered environment. These files are instrumental in configuring the behavior, settings, and interactions between nodes across different sites. Some of the essential .conf files in a multi-site clustering configuration include:
Cluster master (server.conf):
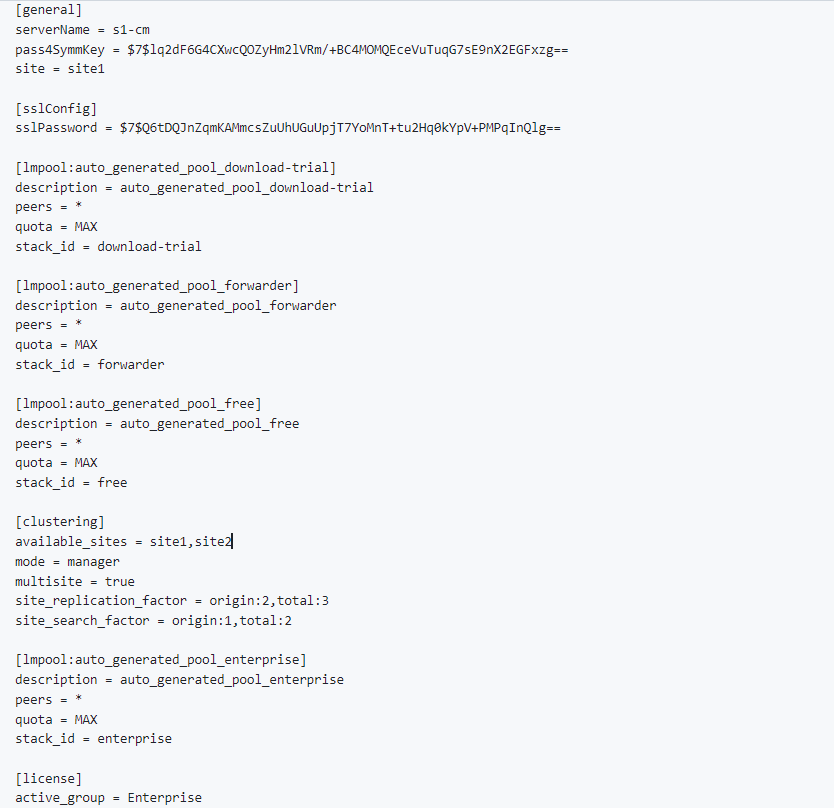
Peer(server.conf):
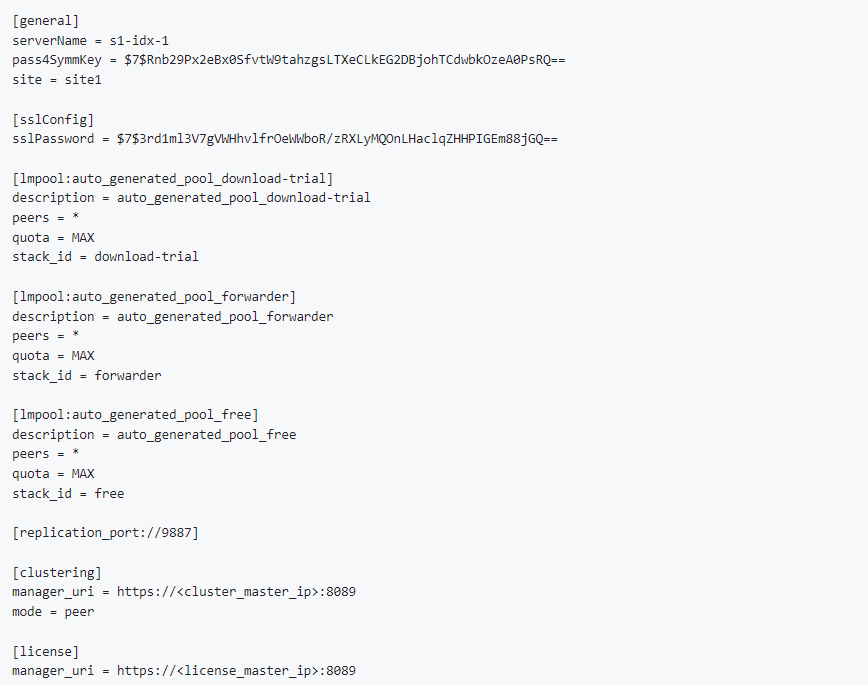
Search Head(server.conf):
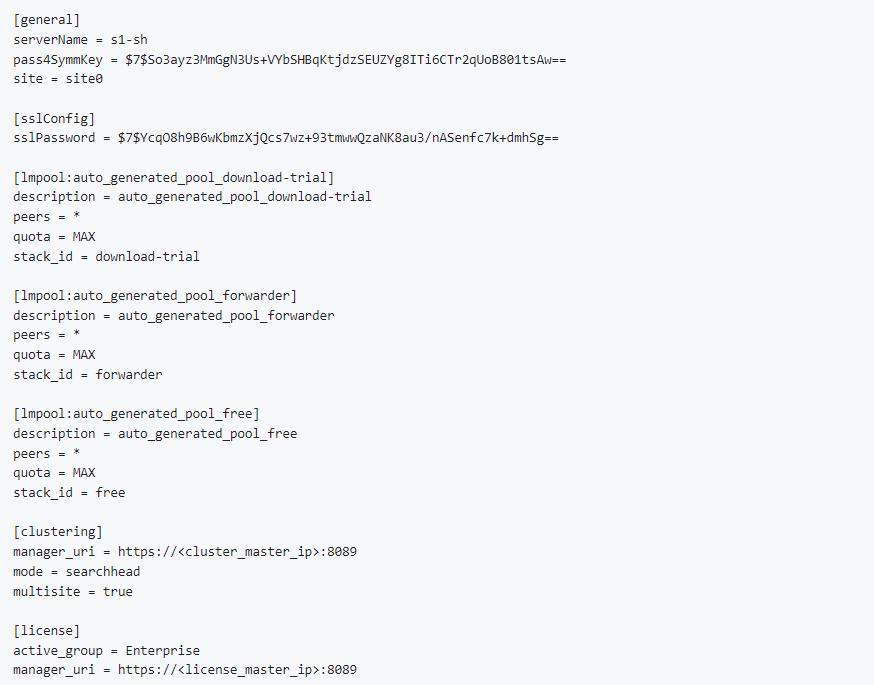
Monitoring console:
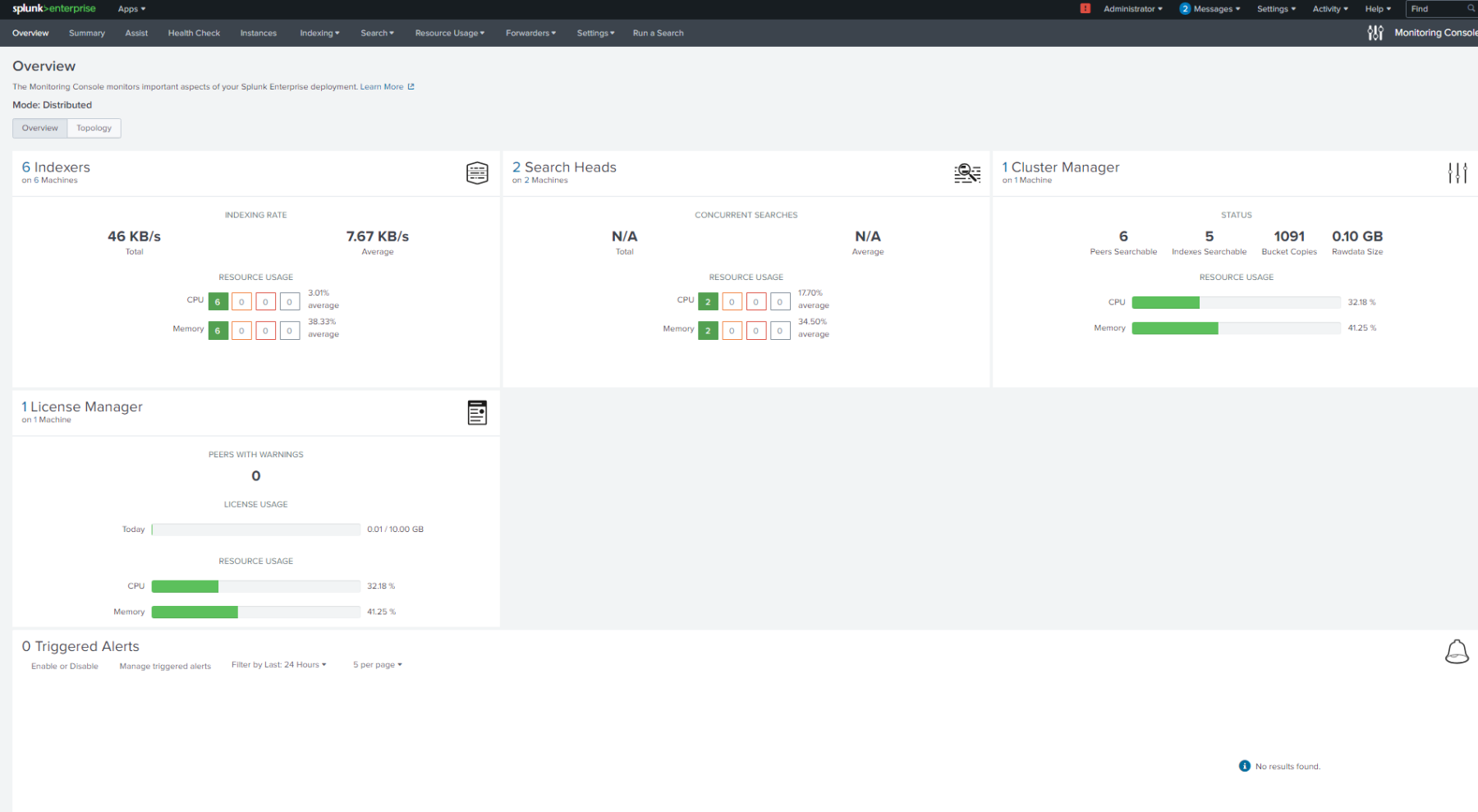
Indexer clustering console:
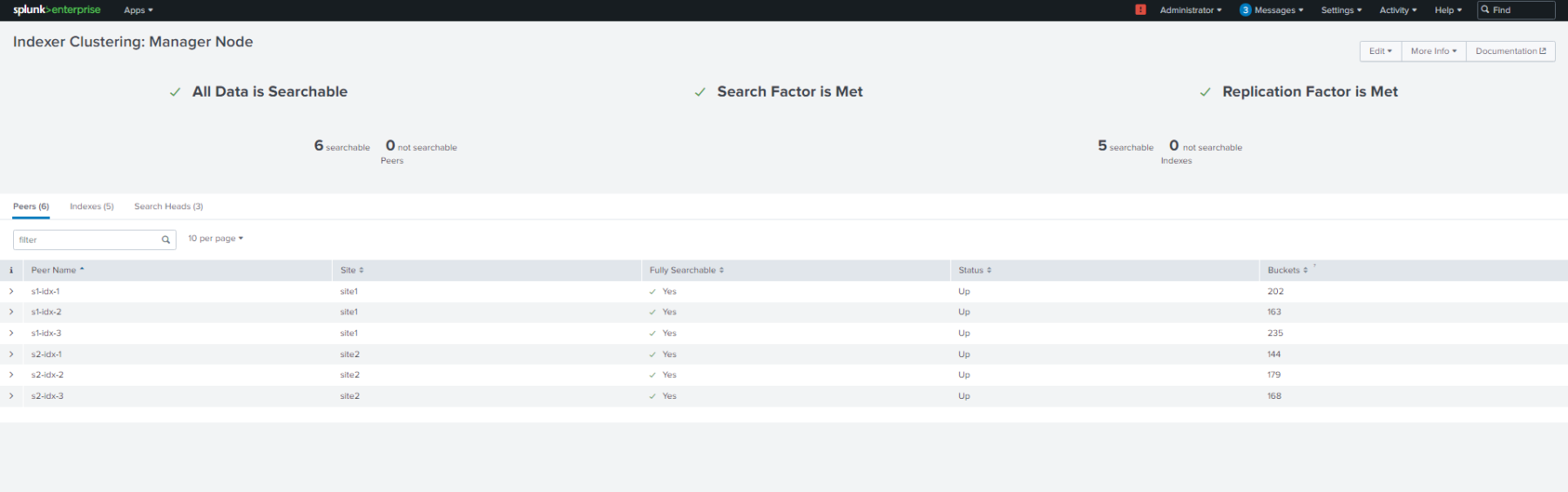
Benefits of multi-site indexer clustering
- By distributing indexing tasks across multiple nodes, the system can effortlessly scale as data volumes increase, ensuring optimal performance without compromising speed.
- In case of node failure or network issues, the cluster remains operational by redirecting tasks to other available nodes, minimizing downtime, and ensuring data availability.
- With nodes placed across different sites, data redundancy and accessibility improve, reducing the risk of data loss due to site-specific failures.
Best practices for implementation
- Strategically placing nodes considering geographical locations and network latency can mitigate performance issues.
- Continuous monitoring of cluster health, performance, and regular maintenance ensures optimal functioning and resolves issues promptly.
- Encryption and authentication: Implement robust encryption (SSL certificates) and authentication mechanisms to safeguard data during transmission and access.
In conclusion, multi-site indexer clustering represents a leap forward in the realm of data indexing, offering unparalleled scalability, fault tolerance, and data availability. When implemented thoughtfully and maintained diligently, this approach empowers organizations to manage their data efficiently across distributed environments, paving the way for enhanced performance and reliability.
About Positka:
Being a Splunk Singapore partner, Positka specializes in high-end technology solutions to help businesses improve their overall IT infrastructure. Founded in 2014, our services include Splunk Services, Cybersecurity & Risk Management, Security Awareness Training, Managed security services, Lean Process Optimization, Robotic Process Enablement Services and Solutions while partnering with other top-tier companies like SentinelOne and so on. We are headquartered in Singapore and operate across India, the US and UK as well.