
Splunk clustering offers a solution as organizations struggle to deal with ever-increasing data volumes by distributing the workload across multiple instances, providing fault tolerance, and improving performance. Splunk is a powerful platform used for searching, analyzing, and visualizing machine-generated data.
Understanding Splunk clustering
Key components:
Indexer Nodes: Responsible for indexing and storing data.
Search Head: Facilitates searches and visualization of indexed data.
Cluster Master: Manages configuration and coordination among cluster nodes.
Forwarders: Agents that send data to the indexer nodes.
Types of clusters:
Indexer Cluster: Stores and indexes data.
Search Head Cluster: Handles search requests and provides a unified interface.
Indexer clustering is primarily of two types:
- Single-site indexer clustering
- Multi-site indexer clustering
In this blog, we’ll only look at one type of clustering, which is single-site indexer clustering.
What exactly is single-site indexer clustering? A specially configured group of Splunk Enterprise Indexers that replicate external data so that they maintain multiple copies of the data. Indexer clusters promote high availability and disaster recovery. (source: Splunk)
Visit Positka's Splunk page to learn more about the capabilities of Splunk.
There are 3 ways of doing clustering:
- CLI Mode
- .conf Mode
- GUI Mode
CLI Mode:
The Command Line Interface (CLI) mode refers to the ability to interact with Splunk software through command-line commands. It allows administrators to perform various management tasks related to setting up, configuring, monitoring, and maintaining a Splunk cluster.
Execute the following on Master node.
./splunk edit cluster-config -mode master –replication_factor 3 -search_factor 2 -secret splunk1234 -cluster_label cluster1
Execute the following on Peer Node.
./splunk edit cluster-config -mode slave -master_uri https://10.0.1.206:8089 -replication_port 8080 -secret splunk1234 -cluster_label cluster1
.conf Mode:
‘.conf’ mode typically refers to the configuration editing mode within the Splunk web interface. When you access and modify configuration settings through the Splunk web interface, you often enter a mode where you can edit .conf files directly or configure settings via GUI (Graphical User Interface).
Master Node ---- server.conf
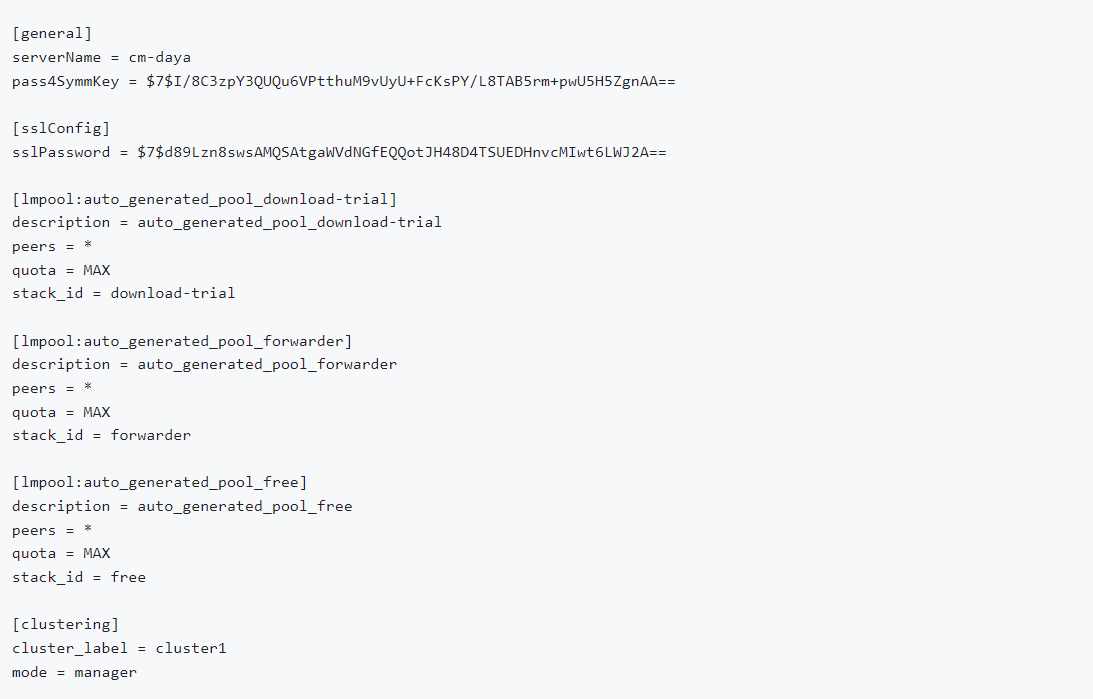
Peer Node --- outputs.conf
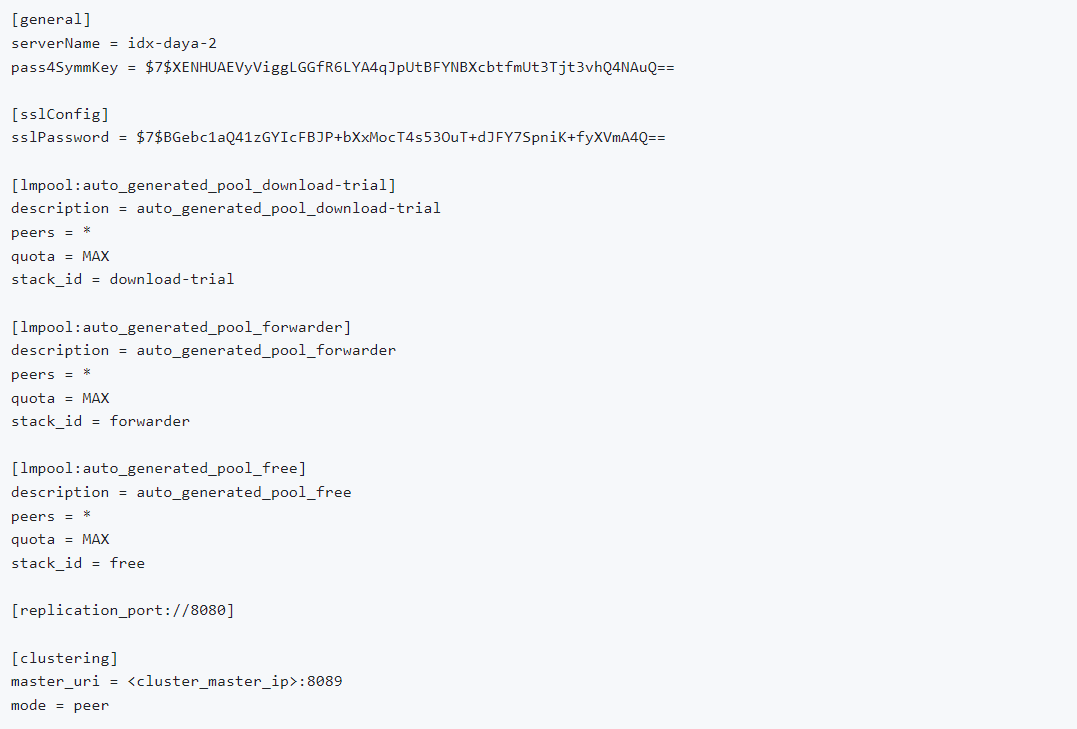
GUI Mode:
Splunk offers a web-based GUI that allows users and administrators to interact with the Splunk software visually. It provides a point-and-click interface to perform various tasks such as searching and analyzing data, creating and managing dashboards, configuring settings, managing users and permissions, monitoring the health of the Splunk environment, and more.
Go to settings and distributed environment --> indexer clustering
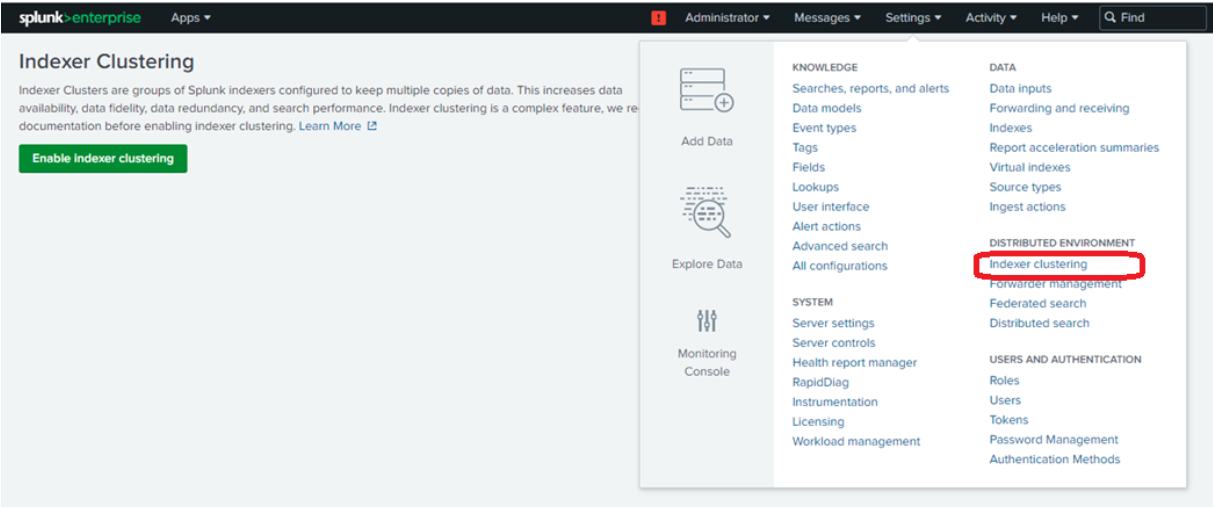
You’ll be provided with three node options: the manager node, peer node, and search head node
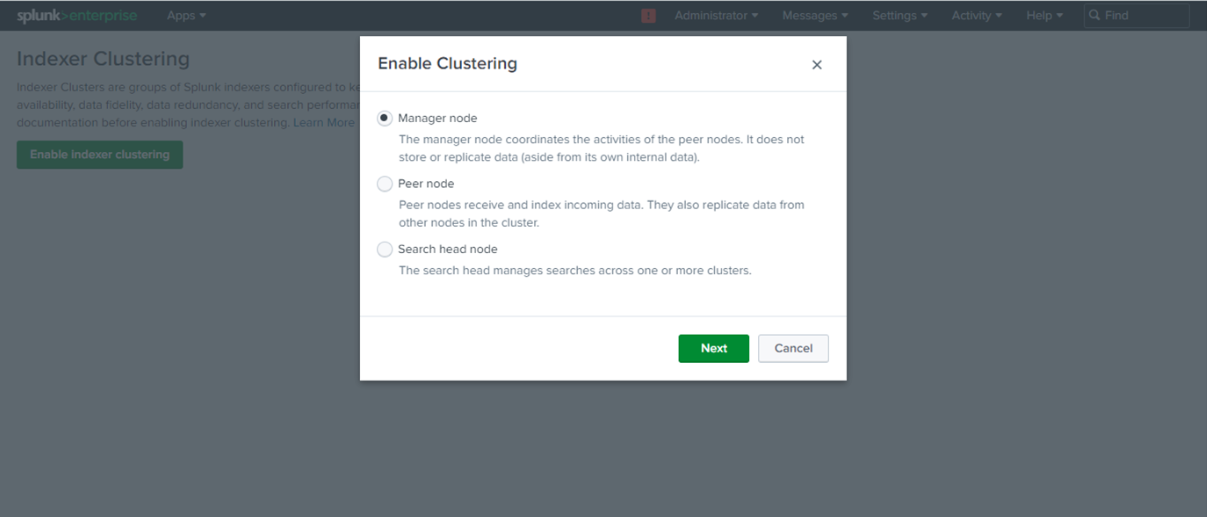
Select the manager node on the Indexer Manager instance and enter the replication factor, search factor, security key and cluster label (This is a best practice when having a monitoring console).
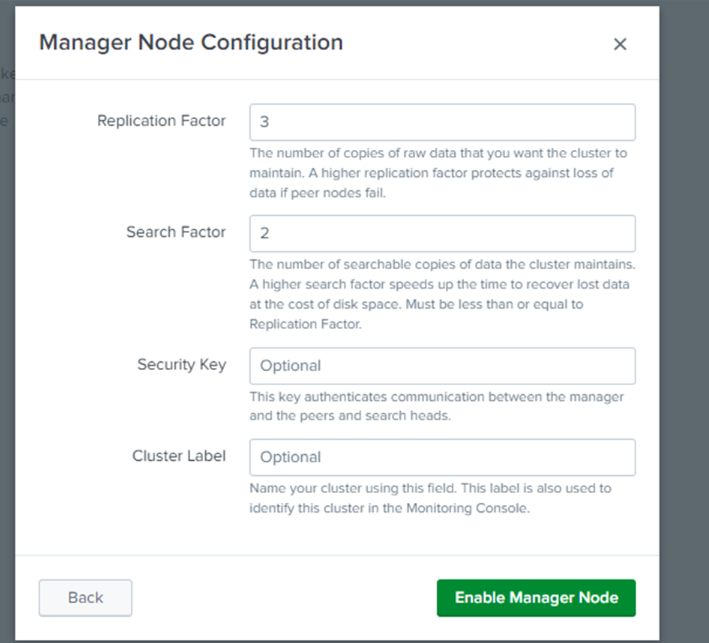
Copy the manager URI of the manager node and paste it in the manager URI text box. Enter 8080 (default number) in the peer replication port to enable the peer node.
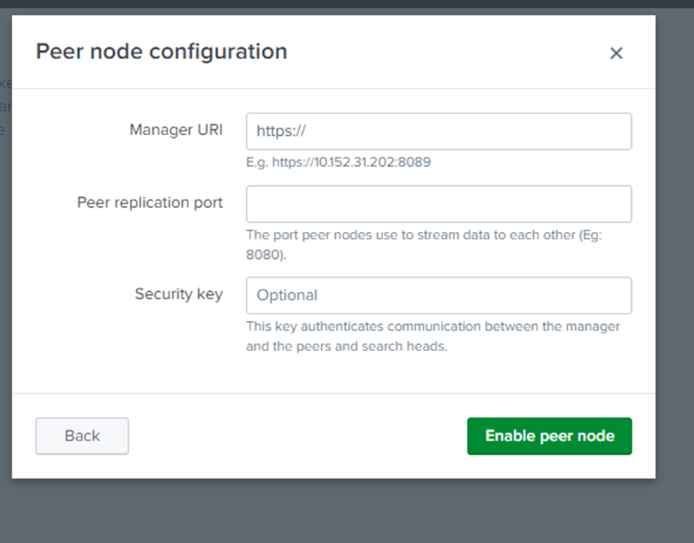
Enter the manager URI in the search head node configuration from the manager node dashboard and the security key (which can be skipped but considered as best practice to do so)
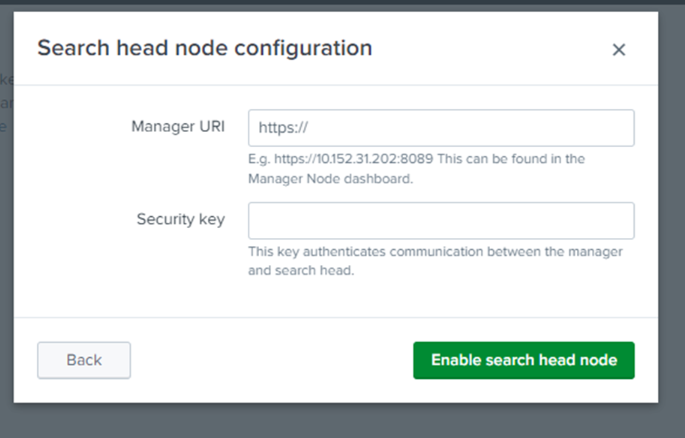
Setting up a Splunk cluster
Planning:
- Capacity Planning: Estimate data volume, growth rate, and performance requirements.
- Network Considerations: Ensure low latency and high bandwidth among cluster nodes.
- Hardware Requirements: Determine the hardware specifications for each node.
Installation:
- Install Splunk on each node, following the recommended guidelines.
- Configure nodes according to their roles (indexer, search head, cluster master, etc.).
Configuration:
- Indexer Cluster Configuration: Set up clustering parameters like cluster replication factor and search factor.
Managing Splunk clusters
Monitoring:
Utilize the Splunk Monitoring Console to track the health and performance of cluster nodes.
Monitor indexing rates, search latency, disk usage, and network throughput.
Scaling:
Add more nodes to the cluster to accommodate increased data volume or query load.
Modify configurations to adjust replication and search factors for scalability.
Maintenance:
Perform regular backups of configuration files, indexes, and other critical data.
Apply Splunk updates and patches in a controlled manner, ensuring minimal downtime.
Best practices and troubleshooting
Best practices:
Follow Splunk's documentation and recommended practices for configuration.
Implement security measures like SSL encryption for inter-node communication.
Regularly review and optimize configurations for better performance.
Troubleshooting:
Use Splunk's diagnostic tools and logs to identify issues.
Common issues include network connectivity problems, configuration mismatches, and resource constraints.
Conclusion:
Splunk clustering offers a robust solution for managing large-scale data and ensuring high availability and performance. By understanding the key components, setting up, managing, and troubleshooting Splunk clusters, organizations can effectively harness the power of Splunk for their data analytics needs.
This technical blog provides an overview of Splunk clustering, from its components and setup to management and best practices. It serves as a guide for administrators and engineers looking to implement and maintain Splunk clusters effectively.
About Positka:
Being a Splunk Singapore partner, Positka specializes in high-end technology solutions to help businesses improve their overall IT infrastructure. Founded in 2014, our services include Splunk Services, Cybersecurity & Risk Management, Security Awareness Training, Managed security services, Lean Process Optimization, Robotic Process Enablement Services and Solutions while partnering with other top-tier companies like SentinelOne and so on. We are headquartered in Singapore and operate across India, the US and UK as well.